-
머신러닝, 딥러닝, 인공지능(AI)의 차이?Computer Science 2021. 3. 22. 20:43
우연히 유튜브에 해당 내용이 나와서 어, 그러고보니 머신러닝 딥러닝 차이는 무엇이고
인공지능과 머신러닝, 딥러닝 이 3가지는 결국 다른거였다고? 하는 생각이 들어서 바로 영상 클릭 후 요약시작.
너무 깊게 들어가지 않고 심플한 설명으로 요약.
AI란 2가지로 나뉘어진다.
(1). Narrow A.I
현재 산업군에서 AI를 사용한다는 것은 이 Narrow AI를 연구해서 적용하였다는 것을 의미한다. Narrow가 좁다라는 의미가 있듯이 하나의 것에 대해서 엄청나게 잘하는 AI를 의미하는데 예를 들어 알파고가 다음 수를 두는 연산을 빠르고 엄청나게 잘 하지만 그 외에 것은 못하기 때문에 Narrow AI가 적용되었다고 볼 수 있다. 집중하는 분야가 좁다고 생각하면 간단하다. (페이스북의 얼굴인식도 그 예이다 - 얼굴은 찾지만 개나 고양이를 찾지는 못하는 것 처럼)
(2). General A.I
일반적으로 영화 등에서 보여지는, 비전공자인 사람들이 보편적으로 상상하는 AI에 대한 분야이다. 결국 사람과 동일하게 혹은 사람보다 더 뛰어나게 사람의 행동, 언어 등을 표현하고 사용하는 AI를 말한다.
그렇다면 이러한 A.I를 어떻게 교육을 시켜서 똑똑하게 연산을 수행하고, 판단할 수 있게끔 하는 것일까?
이 때 머신러닝이 등장한다.
머신러닝
머신러닝은 A.I를 달성하기 위한 수단인데, 이름처럼 machine을 learning하게 만드는 것이다.
학습 방법에는 여러가지가 있겠지만 대표적으로 유명한 2가지가 있다.
예를 들어, 수만개의 핫도그 사진을 기계에게 주고 라벨이나 설명 등 이런 것은 없음.
기계로 하여금 스스로 무엇이 핫도그인지 알아차리게끔 하는 방법으로 그냥 주구장창
핫도그 사진만 주고, 기계 스스로 엄청난 프로세싱 파워 & 데이터 토대로 무엇이 핫도그인지 학습하게 되는 것을 이야기 한다.

출처 - 노마드 코더 만약 음식이 핫도그인지 아닌지 판별하는 앱을 개발한다고 할 때
(1) Unsupervised learning의 경우 - Group and interpret data based only on input data
인간은 해당 learning 방법에서는 데이터를 분류하지 않는다.
(2) Supervised learning의 경우 - Develop predictive model based on both input and output data
핫도그인지 아닌지 핫도그의 특성에 대한 Label(라벨)을 만들어 붙이게 된다.
- 핫도그에는 소세지가 있다
- 핫도그는 길쭉하다
- 핫도그 위에는 소스가 뿌려져 있다.
- 핫도그는 빵 사이에 끼여진 형태이다.
위와 같은 것이 라벨들인데, 이를 통해 기계에게 무엇이 핫도그인지 교육시킨다.
이 후 수만개의 음식을 기계에 전달한다면 우리가 전달해준 라벨들을 통해서 기계는 판단을 하게 된다. 아래처럼.
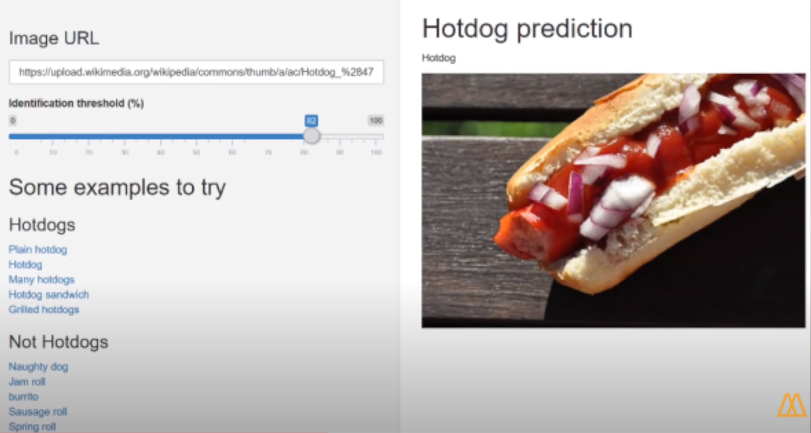
사진출처 - 노마드코더 유튜브 따라서 기계가 자율적으로 판단을 하는 것이 아니라, 확률을 토대로 이야기 하는 것을 의미한다.
수학적 통계를 토대로 확률적으로 95% 정도의 핫도그일 확률을 가졌다! 라고 이야기 하는 것이다.
비슷한 예시로 음악 추천 시스템이 있는데
유저가 좋아하는 음악들을 모아두고 기계에서 내가 좋아하는 아티스트, 이런 리듬을 좋아한다 등을 입력해 놓게 되면 라벨을 기계가 얻게 되고 새로운 음악이 있을 때 유저가 좋아할지 말지 확률상으로 높은 음악들을 픽해서 전달해준다.
딥러닝
딥러닝은 머신러닝을 달성하기 위한 방법이다 -> 머신러닝은 A.I를 달성하기 위한 방법이다.

사진 출처 - 노마드 코더 유튜브 결국 단계적인 것으로 볼 때 피라미드 가장 위에 A.I가 있으며 머신러닝, 딥러닝 순으로 low level로 가게 된다.
딥러닝이라고 불리우는 이유는 'neural network'를 이용하기 때문인데 '뇌'처럼 작동하는 알고리즘이다.
따라서 학습시키려면 엄청나게 많은 데이터가 필요로 하고 아주 길고, 인텐시브한 프로세스라서(?)
프로세싱 파워가 매우 많이 필요하다.
딥러닝은 구글, 테슬라, 엔비디아, ibm 등 메가기업에서 많이 활용 중이다.
사실 이 기업들은 이것을 하기 위해서 엄청난 규모의 데이터를 모으고, 프로세싱 파워를 얻기 위한 돈을 가지고 있다.